Política
Novo método melhora a eficiência dos sistemas de IA do transformador de visão
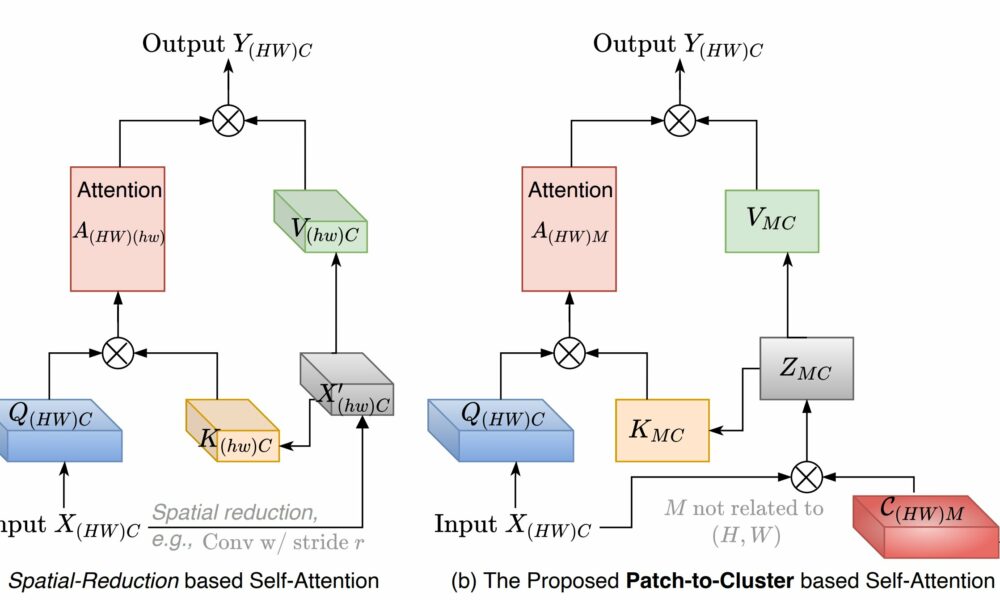
 a autoatenção baseada na redução espacial e (b) o módulo PaCa proposto em aplicações de visão, onde (HW) representa o número de patches na entrada com H e W a altura e a largura, respectivamente, e M um pequeno número predefinido de clusters (por exemplo, M = 100). Crédito: arXiv (2022). DOI: 10.48550/arxiv.2203.11987")
Ilustração de (a) a autoatenção baseada na redução espacial e (b) o módulo PaCa proposto em aplicações de visão, onde (HW) representa o número de patches na entrada com H e W a altura e a largura, respectivamente, e M um pequeno número predefinido de clusters (por exemplo, M = 100). Crédito: arXiv (2022). DOI: 10.48550/arxiv.2203.11987
Os transformadores de visão (ViTs) são tecnologias poderosas de inteligência artificial (IA) que podem identificar ou categorizar objetos em imagens – no entanto, existem desafios significativos relacionados aos requisitos de poder de computação e transparência na tomada de decisões. Os pesquisadores agora desenvolveram uma nova metodologia que aborda ambos os desafios, além de melhorar a capacidade do ViT de identificar, classificar e segmentar objetos em imagens.
Os transformadores estão entre os modelos de IA existentes mais poderosos. Por exemplo, ChatGPT é uma IA que usa arquitetura transformadora, mas as entradas usadas para treiná-la são de linguagem. Os ViTs são IA baseados em transformadores treinados usando entradas visuais. Por exemplo, os ViTs podem ser usados para detectar e categorizar objetos em uma imagem, como identificar todos os carros ou todos os pedestres em uma imagem.
No entanto, os ViTs enfrentam dois desafios.
Primeiro, os modelos de transformadores são muito complexos. Em relação à quantidade de dados conectados à IA, os modelos de transformadores exigem uma quantidade significativa de poder computacional e usam uma grande quantidade de memória. Isso é particularmente problemático para ViTs, porque as imagens contêm muitos dados.
Em segundo lugar, é difícil para os usuários entender exatamente como os ViTs tomam decisões. Por exemplo, você pode ter treinado um ViT para identificar cães em uma imagem. Mas não está totalmente claro como o ViT está determinando o que é um cachorro e o que não é. Dependendo da aplicação, entender o processo de tomada de decisão do ViT, também conhecido como interpretabilidade do modelo, pode ser muito importante.
A nova metodologia ViT, chamada de “Patch-to-Cluster Attention” (PaCa), aborda ambos os desafios.
“Enfrentamos o desafio relacionado às demandas computacionais e de memória usando técnicas de agrupamento, que permitem que a arquitetura do transformador identifique e foque melhor os objetos em uma imagem”, diz Tianfu Wu, autor correspondente de um artigo sobre o trabalho e professor associado da engenharia elétrica e de computação na North Carolina State University.
“Clustering é quando a IA agrupa seções da imagem, com base nas semelhanças encontradas nos dados da imagem. Isso reduz significativamente as demandas computacionais no sistema. Antes do clustering, as demandas computacionais para um ViT são quadráticas. Por exemplo, se o sistema quebrar uma imagem em 100 unidades menores, seria necessário comparar todas as 100 unidades entre si – o que seria 10.000 funções complexas.”
“Ao agrupar, podemos tornar isso um processo linear, onde cada unidade menor só precisa ser comparada a um número predeterminado de clusters. Digamos que você diga ao sistema para estabelecer 10 clusters; isso seria apenas 1.000 funções complexas, “Wu diz.
“O agrupamento também nos permite abordar a interpretabilidade do modelo, porque podemos ver como ele criou os clusters em primeiro lugar. Quais recursos ele decidiu serem importantes ao agrupar essas seções de dados? E porque a IA está criando apenas um pequeno número de clusters, podemos olhar para eles com bastante facilidade.”
Os pesquisadores fizeram testes abrangentes de PaCa, comparando-o com dois ViTs de última geração chamados SWin e PVT.
“Descobrimos que o PaCa superou o SWin e o PVT em todos os aspectos”, diz Wu. “O PaCa era melhor na classificação de objetos em imagens, melhor na identificação de objetos em imagens e melhor na segmentação – essencialmente delineando os limites dos objetos em imagens. Também era mais eficiente, o que significa que era capaz de executar essas tarefas mais rapidamente do que o outros ViTs.”
“O próximo passo para nós é ampliar o PaCa treinando em conjuntos de dados fundamentais maiores”.
O paper, “PaCa-ViT: Learning Patch-to-Cluster Attention in Vision Transformers”, será apresentado na Conferência IEEE/CVF sobre Visão Computacional e Reconhecimento de Padrões, realizada de 18 a 22 de junho em Vancouver, Canadá.
Está publicado no arXiv servidor de pré-impressão.
Mais Informações:
Ryan Grainger et al, PaCa-ViT: Learning Patch-to-Cluster Attention in Vision Transformers, arXiv (2022). DOI: 10.48550/arxiv.2203.11987
Conferência: cvpr2023.thecvf.com/
Citação: Novo método melhora a eficiência dos sistemas de IA do transformador de visão (2023, 1º de junho) recuperado em 3 de junho de 2023 em https://techxplore.com/news/2023-06-method-efficiency-vision-ai.html
Este documento está sujeito a direitos autorais. Além de qualquer negociação justa para fins de estudo ou pesquisa privada, nenhuma parte pode ser reproduzida sem a permissão por escrito. O conteúdo é fornecido apenas para fins informativos.
antenapolitica.com.br














-

 Política5 dias atrás
Política5 dias atrásEduardo Leite é criticado por dizer que ‘grande volume de doações’ vai prejudicar o comércio do RS; veja o vídeo
-

 Entretenimento1 semana atrás
Entretenimento1 semana atrásDeltan desmascara Daniela Lima da Rede Globo e apresenta vídeo revelador
-

 Entretenimento1 semana atrás
Entretenimento1 semana atrásRepórter da Jovem Pan pede para Daniela Lima sair do celular
-

 Entretenimento1 semana atrás
Entretenimento1 semana atrásScooby relata problemas de saúde causados pela água das enchentes
-

 Entretenimento6 dias atrás
Entretenimento6 dias atrásApós ser alvo de críticas em Porto Alegre, William Bonner toma atitude e decide se isolar em navio; veja vídeo
-

 Entretenimento1 semana atrás
Entretenimento1 semana atrásJosé de Abreu ‘parte para cima’ de Jojo Todynho e xinga cantora
-

 Entretenimento3 dias atrás
Entretenimento3 dias atrásTony Ramos: quadro de saúde do ator é revelado após cirurgia no cérebro
-

 Entretenimento1 semana atrás
Entretenimento1 semana atrásHumorista não perdoa e “jornalismo” da Rede Globo vira piada; veja o vídeo